

引言:为什么需要理解SQL执行顺序?
在日常的数据库开发中,我们经常编写复杂的SQL查询语句,但很少有人深入思考SQL引擎是如何解析和执行这些语句的。理解SQL语句的执行顺序不仅能帮助我们编写更高效、更准确的查询,还能在遇到性能问题时快速定位瓶颈,优化查询逻辑。
本文将通过一个典型的SQL查询示例,深入剖析SQL语句的完整执行流程,揭示每个关键子句在查询过程中的作用和时机。
一、SQL查询语句的完整结构
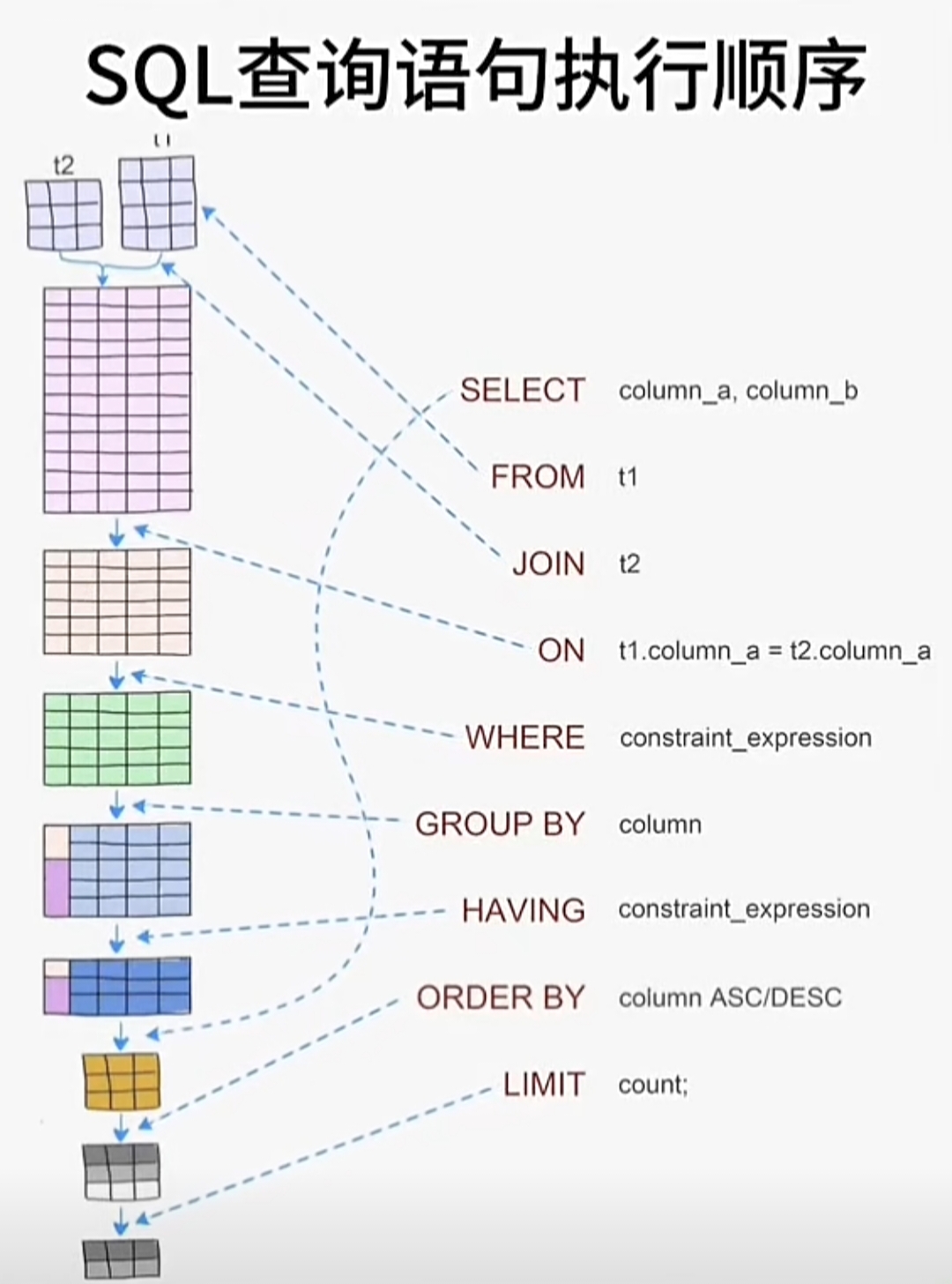
首先,让我们回顾一个标准的SQL查询语句结构:
SELECT column_a, column_b
FROM t1
JOIN t2
ON t1.column_a = t2.column_a
WHERE constraint_expression
GROUP BY column
HAVING constraint_expression
ORDER BY column ASC/DESC
LIMIT count;
从语法结构上看,SELECT语句似乎是从SELECT子句开始的,但实际上SQL引擎的执行顺序与书写顺序完全不同。这种"声明式"的特性正是SQL语言的魅力所在——我们只需告诉数据库"想要什么",而不需要关心"如何获取"。
二、SQL查询的实际执行顺序

2.1 执行顺序图表
以下是SQL查询的标准执行顺序:
数字越小越先执行
(1) FROM/JOIN
(2) ON
(3) WHERE
(4) GROUP BY
(5) HAVING
(6) SELECT
(7) DISTINCT
(8) ORDER BY
(9) LIMIT/OFFSET
2.2 各阶段详解
阶段1:FROM与JOIN(构建数据源)
这是查询的起点。SQL引擎首先确定要查询哪些表,以及这些表如何连接。
-- 从两个表中获取数据
FROM employees e
JOIN departments d ON e.dept_id = d.id
执行过程:
- 读取employees表的所有行
- 读取departments表的所有行
- 根据ON条件执行连接操作
- 生成一个临时的"笛卡尔积"结果集(在应用ON条件之前)
性能影响:
- 表的大小直接影响此阶段的性能
- 连接类型(INNER JOIN、LEFT JOIN等)决定了如何处理不匹配的行
- 没有索引的连接操作可能导致性能灾难
阶段2:ON(连接条件过滤)
在连接操作中,ON子句用于指定表之间如何关联。这与WHERE子句相似,但作用时机更早。
-- ON子句
FROM orders o
JOIN customers c ON o.customer_id = c.id AND c.country = 'USA'
关键区别:
- ON:在连接时过滤,决定哪些行参与连接
- WHERE:在连接后过滤,决定最终结果集中保留哪些行
阶段3:WHERE(行级过滤)
WHERE子句对FROM/JOIN阶段生成的结果集进行过滤,只保留满足条件的行。
-- WHERE
WHERE e.salary > 50000
AND e.hire_date > '2020-01-01'
AND d.name = 'Engineering'
重要特性:
- WHERE在GROUP BY之前执行
- WHERE子句中不能使用聚合函数(如SUM、COUNT)
- 有效的WHERE条件可以利用索引,显著提高查询性能
阶段4:GROUP BY(分组聚合)
将数据按照指定列分组,为聚合计算做准备。
-- GROUP BY
GROUP BY d.name, e.gender
执行过程:
- 根据GROUP BY的列对行进行分组
- 每组生成一行在最终结果集中
- 为后续的HAVING和SELECT阶段做准备
注意事项:
- GROUP BY之后,SELECT中只能包含分组列或聚合函数
- 分组操作的性能消耗与数据分布和分组列基数相关
阶段5:HAVING(分组后过滤)
HAVING对GROUP BY生成的分组结果进行过滤,类似于WHERE,但作用在分组后。
-- HAVING
HAVING COUNT(*) > 5
AND AVG(e.salary) > 60000
与WHERE的关键区别:
- WHERE过滤单个行,HAVING过滤分组
- HAVING可以使用聚合函数,WHERE不能
- HAVING在GROUP BY之后执行,WHERE在之前
阶段6:SELECT(选择列)
这是语法中最先出现的部分,但实际执行较晚。SELECT确定最终结果集中包含哪些列。
-- SELECT
SELECT
d.name as department_name,
e.gender,
COUNT(*) as employee_count,
AVG(e.salary) as avg_salary
重要特性:
- 可以包含原始列、计算列、聚合函数
- 使用AS关键字为列定义别名
- 此时可以应用DISTINCT关键字去重
阶段7:DISTINCT(去重)
如果查询中包含DISTINCT关键字,在此阶段去除重复行。
-- DISTINCT
SELECT DISTINCT department_id, job_title
性能考虑:
- DISTINCT需要对结果集进行排序和比较,可能影响性能
- 在大型数据集上使用DISTINCT需要谨慎
阶段8:ORDER BY(排序)
对最终结果集进行排序。由于在SELECT之后执行,可以使用SELECT中定义的列别名。
-- ORDER BY
ORDER BY avg_salary DESC, department_name ASC
排序成本:
- 如果排序的数据量很大,可能需要在磁盘上执行外部排序
- ORDER BY通常无法使用索引,除非索引顺序与排序顺序完全匹配
- 使用LIMIT可以降低排序成本
阶段9:LIMIT/OFFSET(结果集限制)
最后一步,限制返回的行数,常用于分页查询。
-- LIMIT
LIMIT 20 OFFSET 40 -- 跳过前40行,返回接下来的20行
性能优化:
- LIMIT可以显著减少网络传输和客户端处理的数据量
- 但在大数据集上,结合OFFSET可能导致性能问题(需要扫描并跳过大量行)
三、性能优化实践
3.1 利用执行顺序优化查询
理解执行顺序可以帮助我们编写更高效的查询:
-- 优化前:在WHERE中使用子查询
SELECT *
FROM orders
WHERE customer_id IN (
SELECT customer_id
FROM customers
WHERE country = 'USA'
)
AND order_date > '2023-01-01';
-- 优化后:使用JOIN,让优化器有机会重新安排执行计划
SELECT o.*
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE c.country = 'USA'
AND o.order_date > '2023-01-01';
3.2 索引策略
基于执行顺序设计索引:
- WHERE和JOIN条件:为WHERE子句和JOIN的ON条件中的列创建索引
- GROUP BY和ORDER BY:为分组和排序列创建复合索引
- 覆盖索引:创建包含SELECT中所有列的索引,避免回表查询
-- 为上述查询创建优化索引
CREATE INDEX idx_employees_dept_salary
ON employees(department_id, salary);
CREATE INDEX idx_departments_id_name
ON departments(department_id, department_name);
四、如何查看执行计划
了解执行顺序的最好方法是查看查询的执行计划:
-- MySQL
EXPLAIN
SELECT d.department_name, COUNT(*)
FROM employees e
JOIN departments d ON e.department_id = d.department_id
GROUP BY d.department_name;
-- PostgreSQL
EXPLAIN ANALYZE
SELECT d.department_name, COUNT(*)
FROM employees e
JOIN departments d ON e.department_id = d.department_id
GROUP BY d.department_name;
-- SQL Server
SET SHOWPLAN_ALL ON;
GO
SELECT d.department_name, COUNT(*)
FROM employees e
JOIN departments d ON e.department_id = d.department_id
GROUP BY d.department_name;
GO
五、总结
- 书写顺序 ≠ 执行顺序:SELECT虽然写在最前面,但几乎最后执行
- 过滤越早越好:尽可能在WHERE阶段过滤数据,减少后续处理的数据量
- 合理使用索引:基于执行顺序中最常用的过滤和排序条件创建索引
- 查看执行计划:这是优化复杂查询的最佳工具
SQL执行顺序
| 阶段 | 子句 | 主要功能 | 可否使用别名 | 可否使用聚合 |
|---|---|---|---|---|
| 1 | FROM/JOIN | 确定数据源和连接方式 | 否 | 否 |
| 2 | ON | 连接条件过滤 | 否 | 否 |
| 3 | WHERE | 行级过滤 | 否 | 否 |
| 4 | GROUP BY | 数据分组 | 否 | 否 |
| 5 | HAVING | 分组后过滤 | 是 | 是 |
| 6 | SELECT | 选择输出列 | 是 | 是 |
| 7 | DISTINCT | 去除重复行 | 是 | 是 |
| 8 | ORDER BY | 结果排序 | 是 | 是 |
| 9 | LIMIT | 限制行数 | 是 | 是 |
记住这个顺序,像数据库优化器一样思考,编写出高效、优雅的SQL查询语句。
评论区