首页
密码学
编码
算法
Server
Rust
Redis
Linux
数据库
MYSQL
Tools
瞬间
关于
友情链接
DataForge
Easy to understand and humorous
行动起来,活在当下
累计撰写
48
篇文章
累计创建
5
个标签
累计收到
3
条评论
栏目
首页
密码学
编码
算法
Server
Rust
Redis
Linux
数据库
MYSQL
Tools
瞬间
关于
友情链接
DataForge
目 录
CONTENT
以下是
fengyang
的文章
2025-12-24
MYSQL索引失效常见场景 - 数据库性能优化
本文深入剖析MySQL索引失效的六大常见场景:表达式计算、数据类型不匹配、模糊查询前缀问题、复合索引最左匹配原则、OR条件查询及负向查询。从B+树索引原理出发,解释失效机制并提供针对性解决方案,如改写计算条件、确保类型一致、优化LIKE模式、设计复合索引顺序、使用UNION替代OR等。强调通过执行计划分析验证索引效果,遵循“纯净索引列”“类型严格匹配”“覆盖索引”等原则,结合持续监控与工具辅助,构建高效数据访问层,系统性提升数据库查询性能。
2025-12-24
14
0
0
MYSQL
2025-12-23
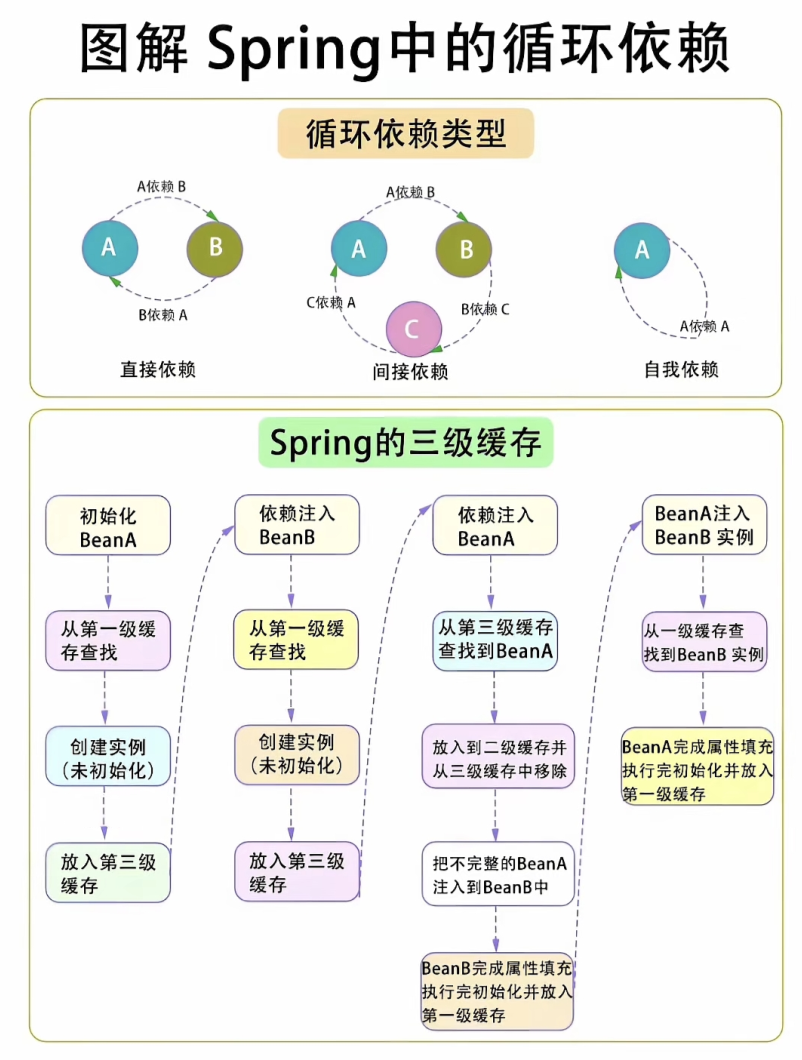
Spring循环依赖解析与三级缓存机制
本文深入剖析Spring框架解决循环依赖的三级缓存机制。该机制通过singletonObjects(完全初始化Bean)、earlySingletonObjects(半成品Bean)和singletonFactories(对象工厂)三级缓存协同工作:实例化时将半成品工厂存入三级缓存,依赖注入时若发现循环依赖则提前暴露半成品引用至二级缓存,完成初始化后升级至一级缓存。此机制支持字段/Setter注入的循环依赖,但无法解决构造器注入及原型Bean的循环依赖。文章强调开发者应理解机制而非依赖它,建议通过事件驱动、门面模式等设计优化架构,避免循环依赖的产生。
2025-12-23
17
1
0
Java
2025-12-11
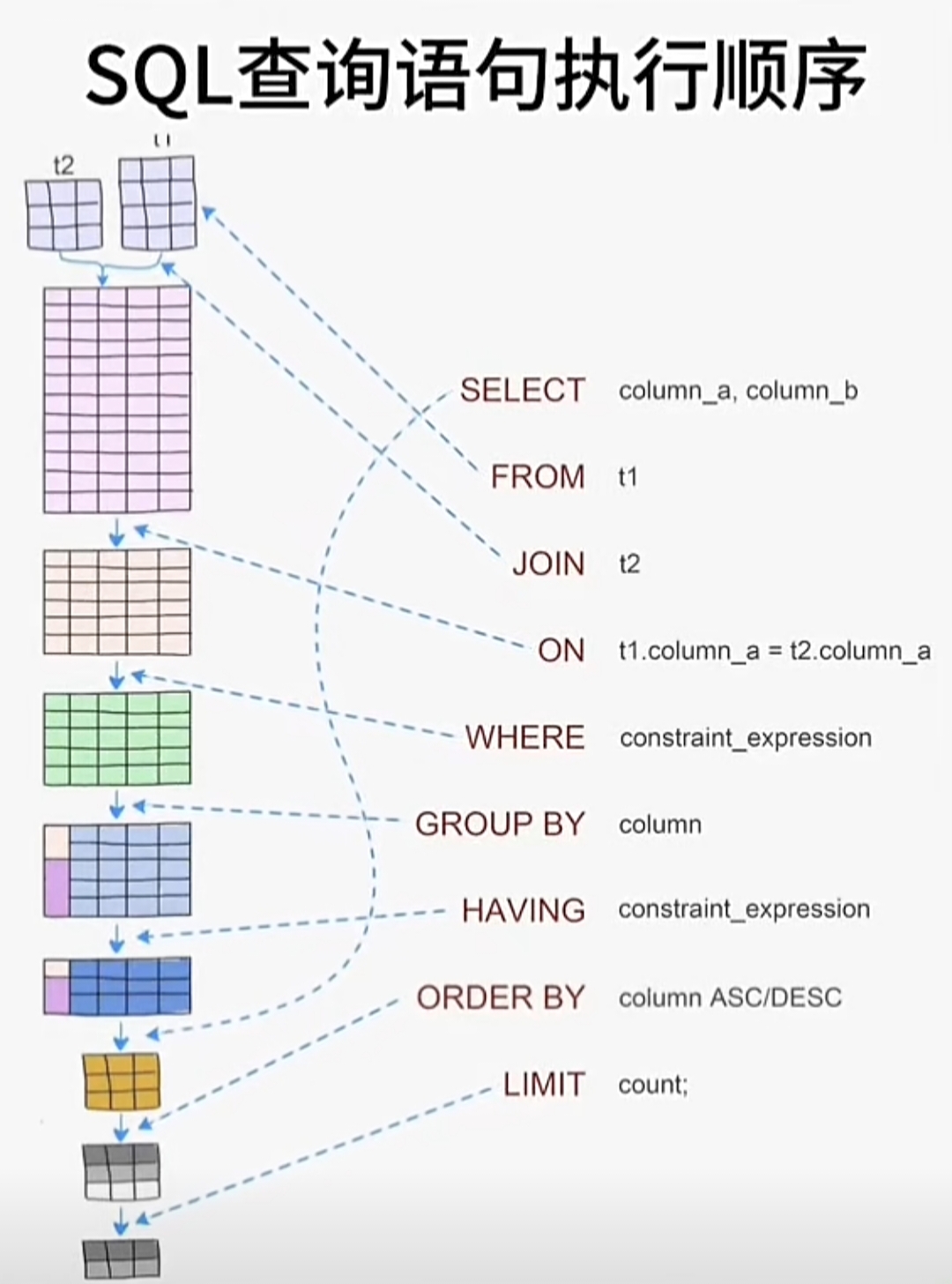
SQL查询语句执行顺序深度解析:从语法到执行的完整旅程
理解SQL执行顺序对高效数据库查询至关重要。SQL实际执行顺序并非按书写顺序,而是从FROM/JOIN开始,依次经过ON、WHERE、GROUP BY、HAVING、SELECT、DISTINCT、ORDER BY,最后到LIMIT/OFFSET。掌握此顺序可优化性能,如尽早过滤数据减少处理量、合理使用索引加速查询,并通过执行计划分析瓶颈,从而编写更高效的SQL语句。
2025-12-11
28
0
1
数据库
2025-12-10
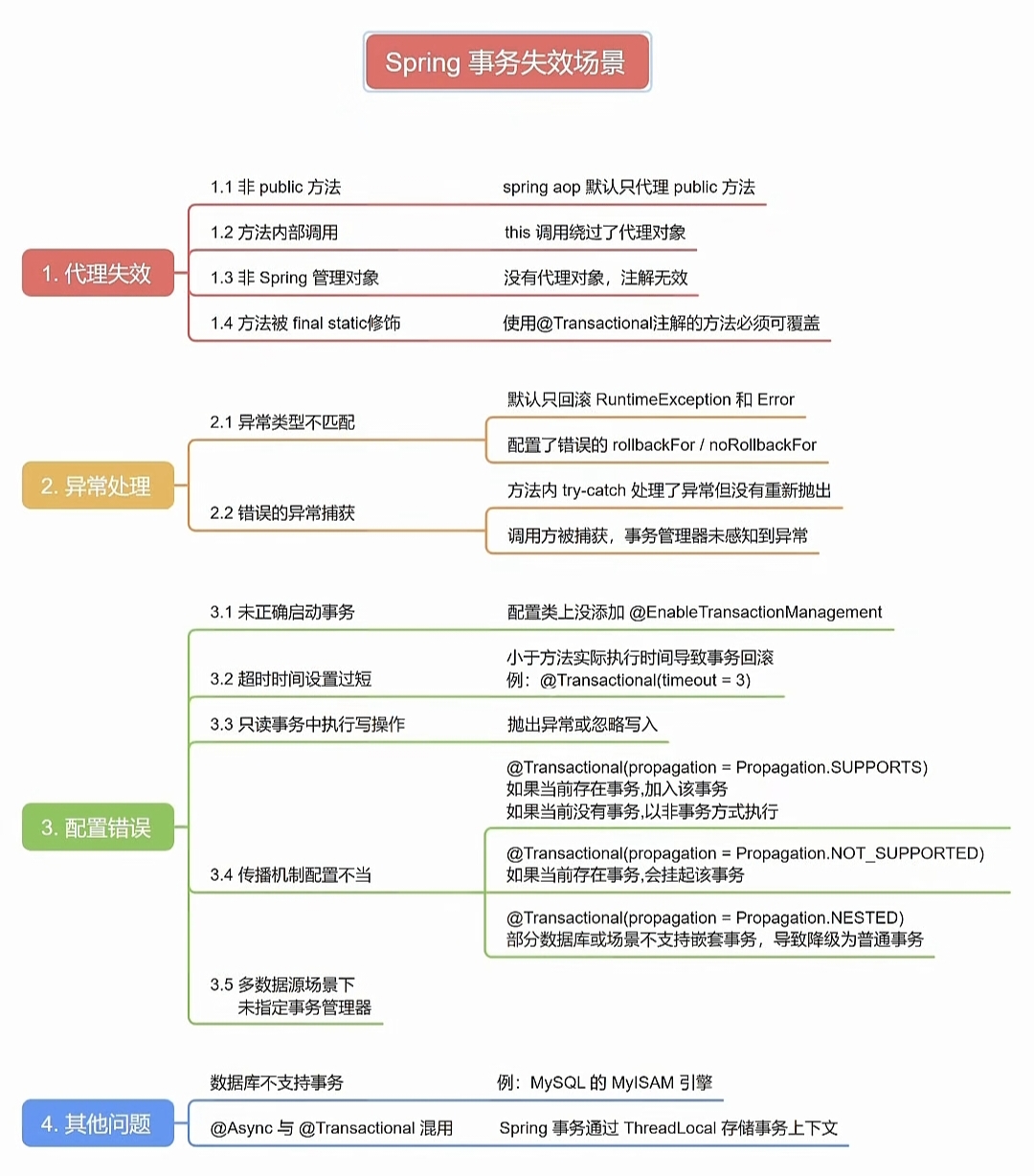
Spring 事务失效的八大场景深度解析
本文系统分析了Spring事务失效的常见原因及解决方案。核心问题包括:代理机制失效(非public方法、内部调用、final/static方法)、异常处理不当(异常类型不匹配、异常被吞没)、配置错误(未启用事务管理、超时设置过短、传播机制错误)、数据库层面问题(引擎不支持事务)、并发场景冲突(@Async与@Transactional冲突)。解决需关注方法可见性、异常抛出、事务传播行为配置,并通过调试日志和编程式事务排查问题。理解Spring AOP机制和事务原理是避免失效的关键。
2025-12-10
11
0
0
Java
2025-10-28
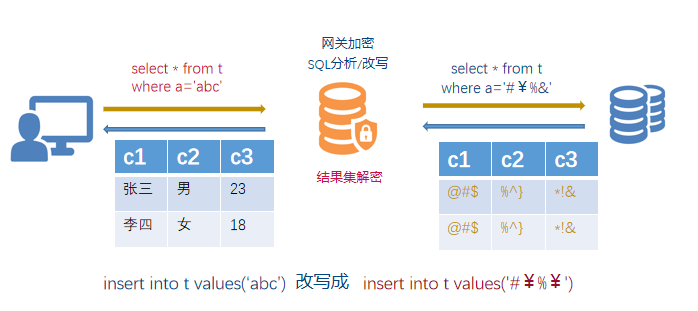
数据库安全网关体系中,对Long、Date类型列加密的方法
本文探讨数据库中Long、Date类型列加密的安全性与业务查询平衡问题。传统加密会破坏数据类型特性,导致查询功能丧失。核心解决方案为格式保留加密(FPE),其通过有限域映射实现加密后数据保持原有格式、长度和类型(如Long仍为数值,Date仍为日期格式),支持等值及范围查询,完美兼容现有数据库模式。FPE虽实现复杂且性能略逊于AES,但有效解决了加密与业务兼容性的核心矛盾。
2025-10-28
24
0
0
数据库
2025-10-22
浅谈常见的八类数据库加密技术
本文概述了加密技术从通信安全向数据全生命周期保护的范式转变。面对大数据时代数据动态流转的挑战,传统边界防御已不足,需转向“保护数据本身”的安全理念。文章深入剖析八种主流加密技术(应用内加密、数据库网关、触发器+视图、TDE、UDF、加密驱动、TFE、FDE),涵盖应用层、数据库层及文件系统层的部署方案,对比其加密粒度、性能、防DBA能力及实施成本。核心结论是:单一技术无法满足所有场景,需根据数据状态(静态/动态/使用中)与业务需求,组合构建纵深防御体系,实现数据流转中的持续安全保护。
2025-10-22
31
0
1
数据库
2025-10-19
Doris SQL解析
Doris SQL解析包含五个核心步骤:1)词法语法分析生成AST(采用jflex/java cup技术);2)语义分析与重写(元信息解析、合法性检查、常量折叠、谓词转join等RBO优化);3)生成单机逻辑计划(构建算子树,进行投影/谓词下推、分区裁剪、Join重排序等优化);4)生成分布式计划(拆分PlanFragment树,支持broadcast/hash partition/colocate/bucket shuffle四种join算法);5)物理执行计划调度(分配BE节点、选择副本、实现并发执行)。整个过程通过递归优化和规则重写,最大化并行度与数据本地化。
2025-10-19
13
0
0
Doris
2025-10-16
Doris
Doris架构分FE(前端)、BE(后端)和存储层:FE负责查询解析、元数据管理,含Leader/Follower保高可用、Observer扩展查询;BE存储数据并分布式执行查询,通过副本保可靠;存储层用列式存储,数据分Tablet存于BE。数据模型有三类:Aggregate按key聚合适合报表汇总;Uniq主键模型保证唯一,分读时/写时合并;Duplicate允许key重复保留明细,适用Ad-hoc查询。选型需根据聚合需求、主键约束等场景确定。
2025-10-16
5
0
0
Doris
2025-10-13
Calcite 元数据定义
Calcite执行流程的核心包括三个部分:元数据定义、优化规则管理和最优计划执行。元数据用于校验SqlNode语法树并为CBO优化提供统计信息,如示例中的JSON文件定义;优化规则被优化器使用以改写逻辑计划并生成最优执行计划;执行器基于最优计划在不同存储引擎上进行执行,确保高效数据处理。
2025-10-13
9
0
0
Calcite
2025-10-11
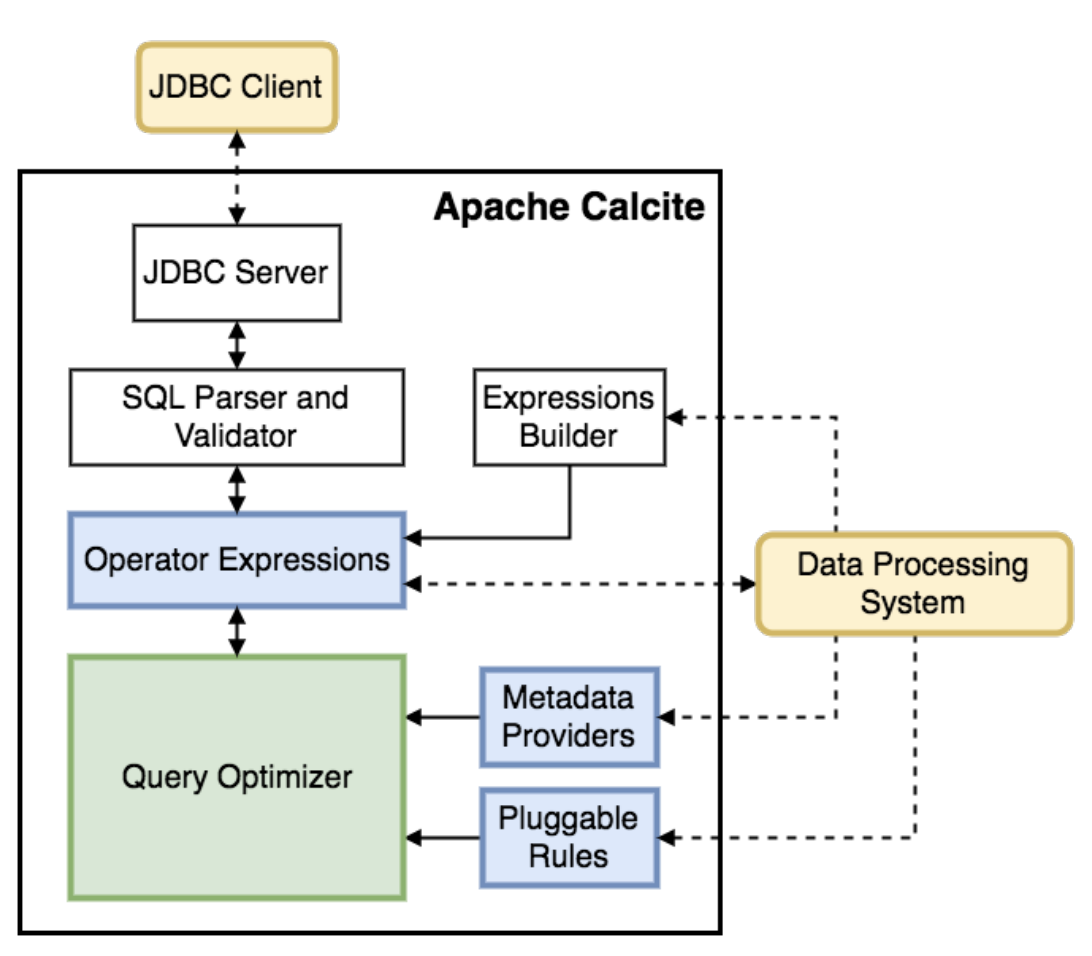
Apache Calcite:构建统一数据查询的基石
Apache Calcite 是开源动态数据管理框架,旨在解决大数据时代的数据孤岛与异构数据源整合挑战。其核心架构以查询优化器为中心,通过 SQL 解析器、验证器将语句转为逻辑关系代数表达式(RelNode),结合 RBO(200+ 优化规则)与 CBO(基于统计信息)生成最优执行计划。框架采用“逻辑与物理分离”设计,支持 JDBC/Java API 调用,并通过可插拔适配器连接 Hive、Elasticsearch 等数据源,提供统一查询层。其模块化架构(如元数据管理、表达式构建)及 CSV 示例验证了跨源查询的灵活性与扩展性。
2025-10-11
6
0
0
Calcite
1
2
3
4
5